
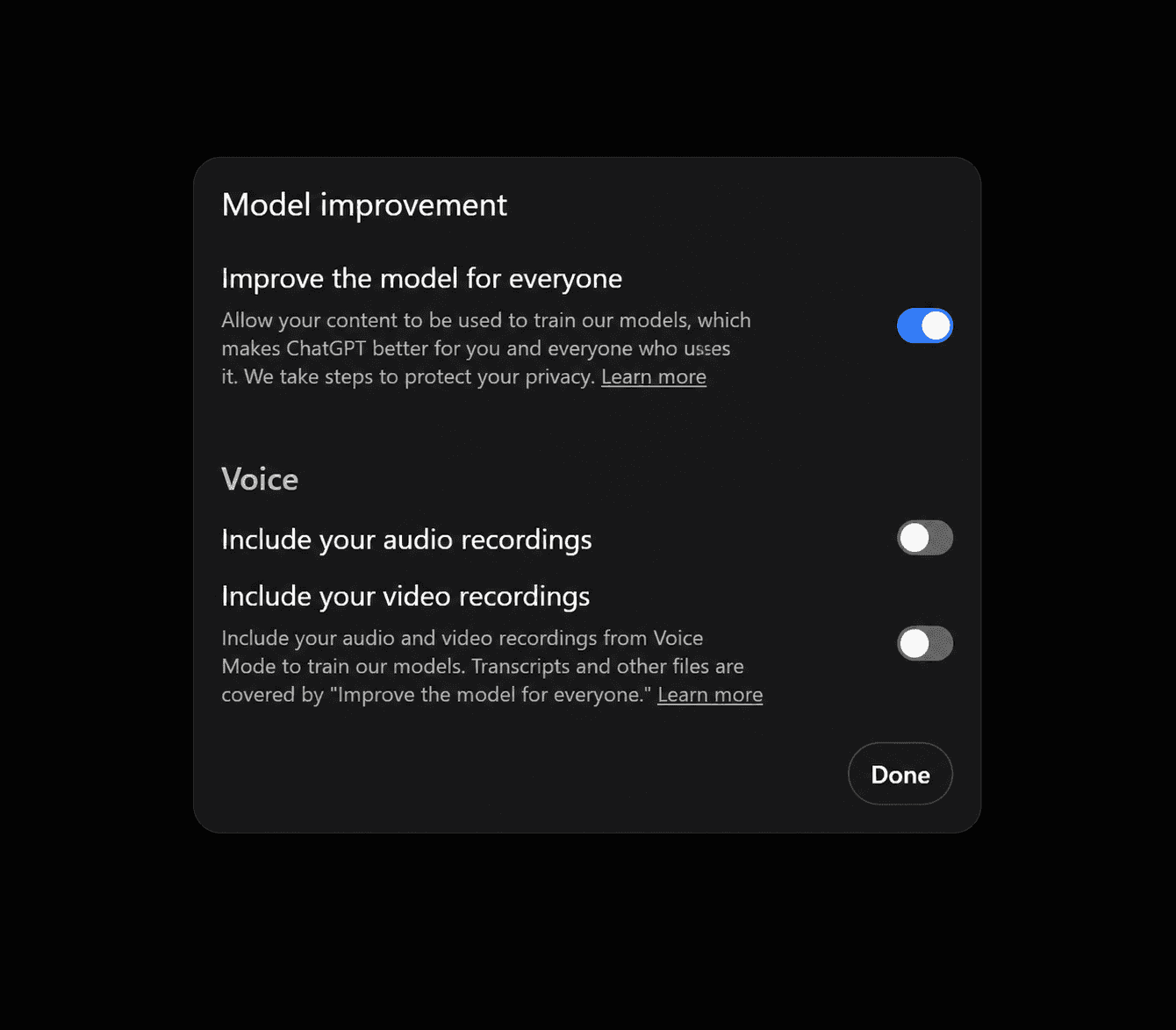
I went into my ChatGPT settings last week to grab a screenshot for a post. The data sharing toggle was switched back to On.
I remember turning it Off a few months ago. I had read the privacy policy, understood the trade off, and made a deliberate choice. Yet there it was. Back On.
Turns out this is a known issue with ChatGPT specifically. OpenAI has reset or re prompted users on this setting during product updates, Terms of Service changes, and when new features were rolled out. Bug or dark pattern or just sloppy engineering? Nobody knows because they have not been transparent about it.
But to be fair, this is not just a ChatGPT problem. Gemini, Claude, Copilot, and most major AI platforms have similar data policies. Some are better. Some are worse. The specifics vary. But the structural issue is the same across the board. Your data, once it enters training, does not come back.
The Toggle Is Not The Problem. But Keep It Off Anyway.
Let me be clear. Turning data sharing off is worth doing. When it is Off, your new conversations do not get used to train the models. That is real protection. It prevents future conversations from entering the training pipeline. Do it. Right now if you have not already.
But here is what the toggle does not do, regardless of which platform you use.
It does not apply retroactively. Everything you did before switching it Off? Already in the dataset.
And more importantly, your toggle only governs what you upload. It does not govern what other people upload. Including documents you created and shared with them.
This distinction matters more for business owners than for casual users. If you are a founder or run a business, your documents contain your competitive advantage. Your pricing strategy. Your positioning framework. The specific way you frame value that took years to develop. A casual user losing a few chat logs is annoying. A business owner losing proprietary positioning is a real problem.
Let me give you a concrete example. I spent eight years refining a proposal document. Eight years of learning what works, what does not, how to frame value, how to price, how to tell a story. I recently used AI to help improve it. Great feedback.
But even with my data sharing set to Off, the person I send this proposal to probably has theirs set to On. Could be ChatGPT, could be Gemini, could be anything. And they are going to upload my document and ask a perfectly reasonable question:
"Summarize this for me." "Evaluate this proposal." "Is this worth opening?"
Seemingly harmless. Saved them time. Convenient. But now some model somewhere has ingested my document. My structure. My pricing logic. The specific language patterns that took years to develop. And I have no idea where it goes from there.
The Biryani Problem
Let me explain this risk in a way that is easier to digest. Pun intended.
Imagine Paradise Biryani (just using them as an example, I have no inside information here) spent 15 years perfecting their recipe. It is their competitive edge. Their reputation. Tourists plan trips around it. They have never published the recipe anywhere.
A staff member who signed an NDA chats with ChatGPT and types the recipe in to refine it. To them it is a smart notepad. They have no idea what they just did. Or maybe a manager uploads the recipe document to Claude to help write a training manual. Or someone asks Gemini to suggest improvements to the cooking process. Different platform, same problem.
This scenario produces not one risk but four. Each with different odds and different implications for a business owner.
# | Scenario | Probability | Why It Matters For Your Business |
|---|---|---|---|
1 | Someone asks "What is Paradise's biryani recipe?" | Low | AI companies say they do not surface private data this way. But if the same recipe appears in enough conversations across enough platforms, it becomes a pattern and the guarantee gets fuzzy. |
2 | Someone asks "What is the best biryani recipe in Hyderabad?" | High | The model has absorbed the recipe as general knowledge. It produces something suspiciously close to Paradise's recipe. No citation, no attribution, no recourse. Completely invisible. This is the risk nobody talks about. |
3 | Someone asks for a biryani recipe and gets a slightly modified version of it | Almost certain at scale | Worse than direct theft in some ways. Unrecognizable, unprovable, and the model genuinely does not know it learned from Paradise. Their competitive advantage just became a commodity. |
4 | Someone asks "What makes Paradise's biryani different from others?" | Plausible | The model synthesizes thousands of Zomato reviews, Instagram posts, and YouTube videos. It never touched the actual recipe. It did not need to. Paradise's own customers unknowingly trained their competition. |
Scenario 1 is the one the AI companies would say is prevented by their policies. Scenarios 2, 3, and 4 are not prevented by any policy on any platform. Because the AI is not retrieving your data. It is expressing learned patterns.

The platform does not matter. The mechanism is the same.
Storage vs Digestion
This is the distinction that matters.
Storage is what we intuitively understand. Your data sits in a folder. Someone can point at it and say "that belongs to them." You can delete it, move it, control who accesses it.
Digestion is what actually happens. Your data enters training and dissolves into the model's weights. It becomes part of the statistical soup that produces outputs. In theory, researchers have shown it is sometimes possible to extract fragments of training data from models. In practice, for a business owner trying to prove that your eight-year-old proposal ended up in someone else's output? Good luck. You cannot extract it in any usable way. You cannot prove it was yours. You cannot delete it once it is in there.
The entire privacy debate is still framed around the storage model. We talk about access control, opt in versus opt out, data retention policies. These things matter. But they address the wrong mechanism.
The real question for a founder or business owner is this. What happens when your proprietary thinking, the stuff that differentiates you in the market, becomes part of a model that your competitors also have access to? Not through theft. Through the accumulated exhaust of normal business behavior. Proposals sent, documents shared, meetings summarized. Each harmless on its own. Together, a slow bleed of what makes you different.
And it does not matter if that model is ChatGPT, Gemini, or something that launches next year. The mechanism is the same. Input goes in. Knowledge gets digested. Output comes out. And you have no idea what part of your thinking just leaked into someone else's result.
What This Means For You
I am not suggesting paranoia. I am suggesting awareness. There is a difference.
First, turn data sharing off right now on every platform you use. ChatGPT, Gemini, Claude, Copilot, all of them. It is not a silver bullet but it is not useless either. It prevents new conversations from entering training. That is real. Do not skip it just because it is imperfect.
Second, assume anything you send digitally can enter a training set on some platform somewhere. Not because someone is out to get you. Because someone was just being convenient. This changes what you share and how you share it.
Third, know the difference between strategic IP and operational content. Your pricing framework, positioning strategy, and proprietary methodology? Keep those close. A standard project update? Less risky.
Fourth, ask the people you share sensitive documents with what they do with them. Most people will not think twice before uploading your document to an AI tool, regardless of which one they prefer. A quick "hey, are you running this through anything?" can save you a lot of trouble.
None of these are perfect solutions. They are adaptations to a new reality.
Data used to be stored and served. Now it is digested, by multiple platforms, in ways we cannot fully track or control. The toggle helps but it is not the whole answer. Control is not a switch. It is a habit. And most of us are still building that habit.